🎁 Our holiday gift to you: Experiments is here!
Backed by

Ship your AI app with confidence
The all-in-one platform to monitor, debug and improve
production-ready LLM applications.





The ability to test prompt variations on production traffic without touching a line of code is magical. It feels like we’re cheating; it’s just that good!


Nishant Shukla
Sr. Director of AI
Get integrated in seconds
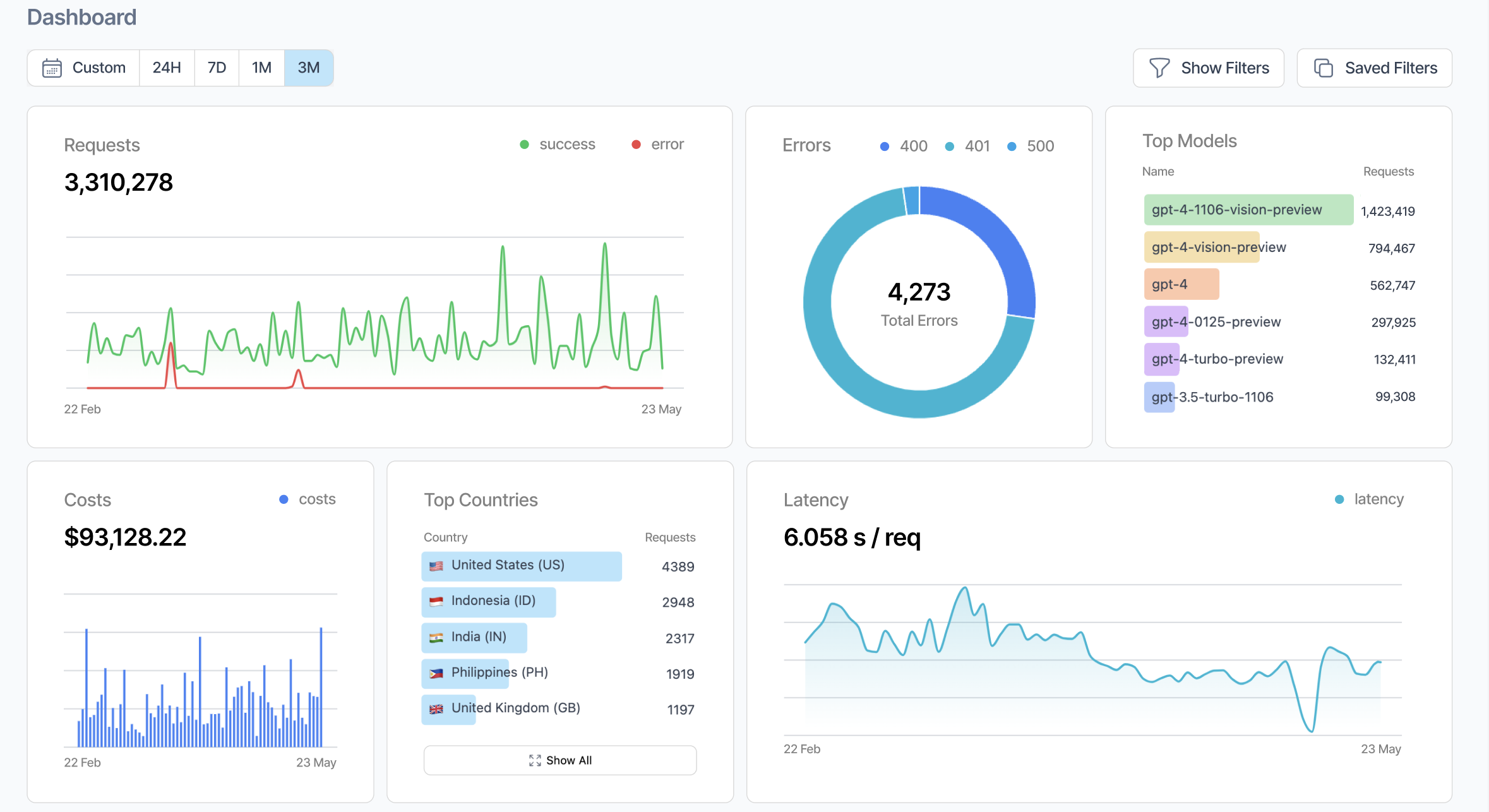
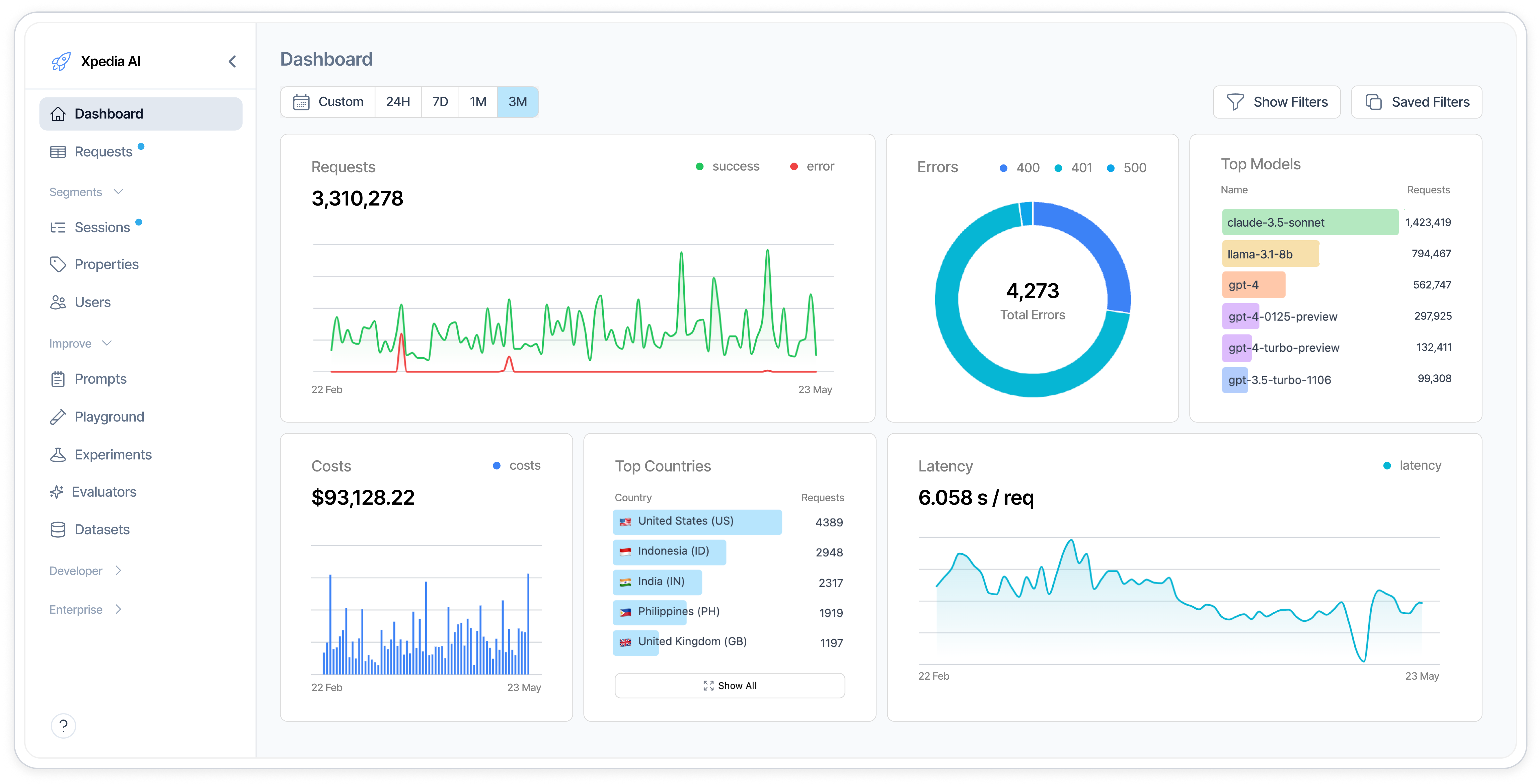
Use any model and monitor applications at any scale.





“Probably the most impactful one-line change I've seen applied to our codebase.”
What if I don’t want Helicone to be in my critical path.
There are two ways to interface with Helicone - Proxy and Async. You can integrate with Helicone using the async integration to ensure zero propagation delay, or choose proxy for the simplest integration and access to gateway features like caching, rate limiting, API key management.
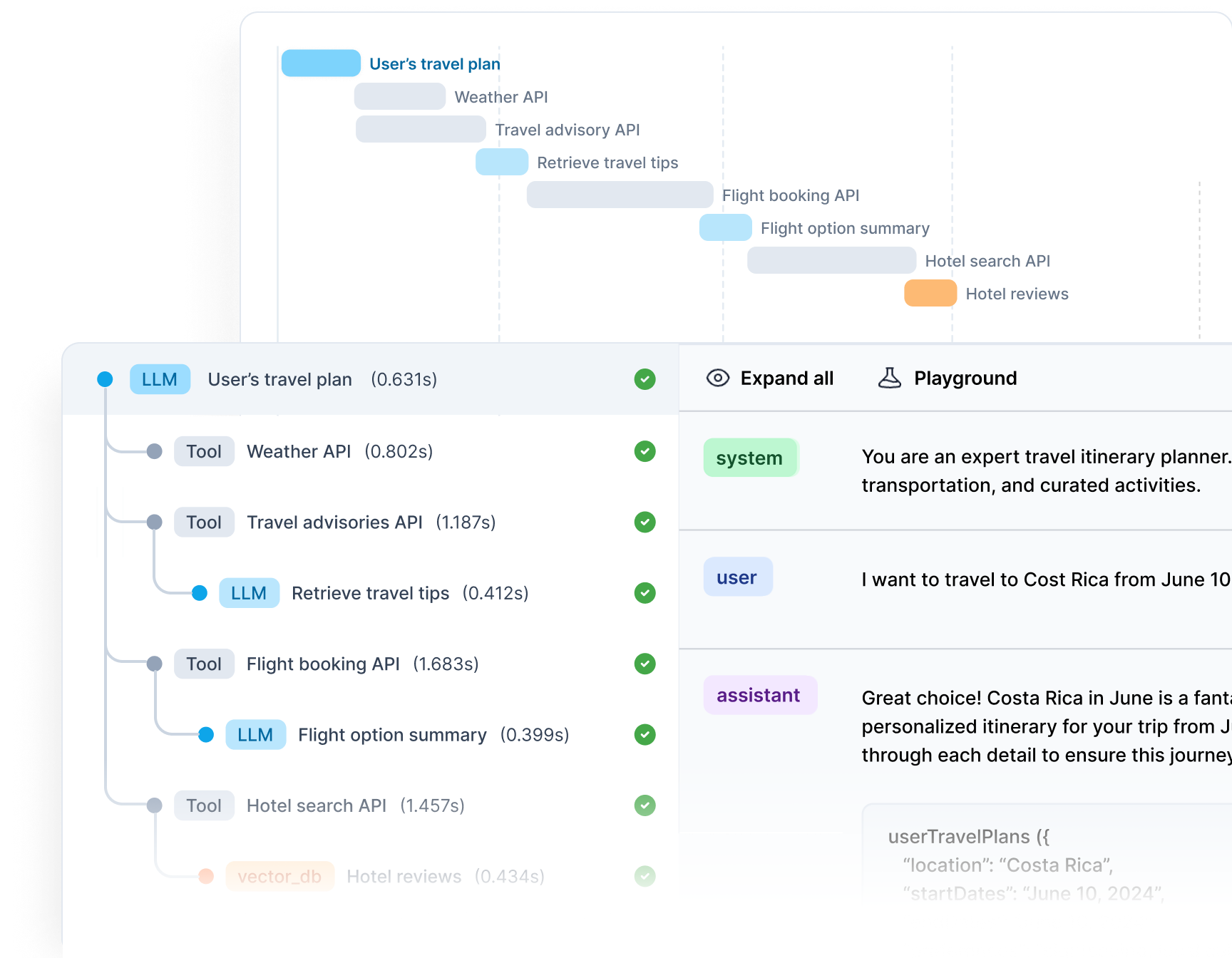
Designed for the entire LLM lifecycle
The CI workflow to take your LLM application from MVP to production, and from production to perfection.
02
Prevent regression and improve quality over-time
Monitor performance in real-time and catch regressions pre-deployment with LLM-as-a-judge or custom evals
What is online and offline evaluation?
Online evaluation tests systems in real-time using live data and actual user interactions. It’s useful to capture dynamic real-world scenarios.
In contrast, offline evaluation occurs in controlled, simulated environments using previous requests or synthetic data, allowing safe and reproducible system assessment before deployment.
03
Push high-quality prompt changes to production
Tune your prompts and justify your iterations with quantifiable data, not just “vibes”.
| Messages | Original | Prompt 1 | Prompt 2 | |
|---|---|---|---|---|
| {"role": "system", "content": "Get... | Queued... | Queued... | Queued... | |
| {"role": "system", "content": "Get... | Queued... | Queued... | Queued... | |
| {"role": "system", "content": "Get... | Queued... | Queued... | Queued... | |
| {"role": "system", "content": "Get... | Queued... | Queued... | Queued... | |
| {"role": "system", "content": "Get... | Queued... | Queued... | Queued... | |
| {"role": "system", "content": "Get... | Queued... | Queued... | Queued... | |
| {"role": "system", "content": "Get... | Queued... | Queued... | Queued... | |
| {"role": "system", "content": "Get... | Queued... | Queued... | Queued... | |
| {"role": "system", "content": "Get... | Queued... | Queued... | Queued... | |
| {"role": "system", "content": "Get... | Queued... | Queued... | Queued... | |
| {"role": "system", "content": "Get... | Queued... | Queued... | Queued... |
LLM as a judge
Similarity
77%
LLM as a judge
Humor
81%
LLM as a judge
SQL
94%
RAG
ContextRecall
63%
Composite
StringContains
98%

Deploy on-prem
Cloud-host or deploy on-prem with our production-ready HELM chart for maximum security. Chat with us about other options.
Get in touch
Built by Helicone
API Cost Calculator
Compare LLM costs with the largest open-source API pricing database with 300+ models and providers such as OpenAI, Anthropic and more.
Built by Helicone
Open Stats
The largest public AI conversation datasets consisting of all of Helicone’s LLM usage data. All anonymized.
Questions & Answers
Thank you for an excellent observability platform! . I pretty much use it for all my AI apps now.


Hassan El Mghari
Devrel Lead